2025 後半に OpenOcean/Dolphin の著作権表示に関する記事をいくつか書いた。
OpenDolphin/Ocean ソースコード利用指針
その目的は、間違いだらけの AI まとめ対策のほかにソースコードを利用するための指針を示すという意図もあった。
最近では、@MedRecMate さん(丸口勇人先生?)が dolphin のソースコードを OpenDolphinNext で再利用している。
LICENSE の改竄はなかなか気がつきにくいところだ。
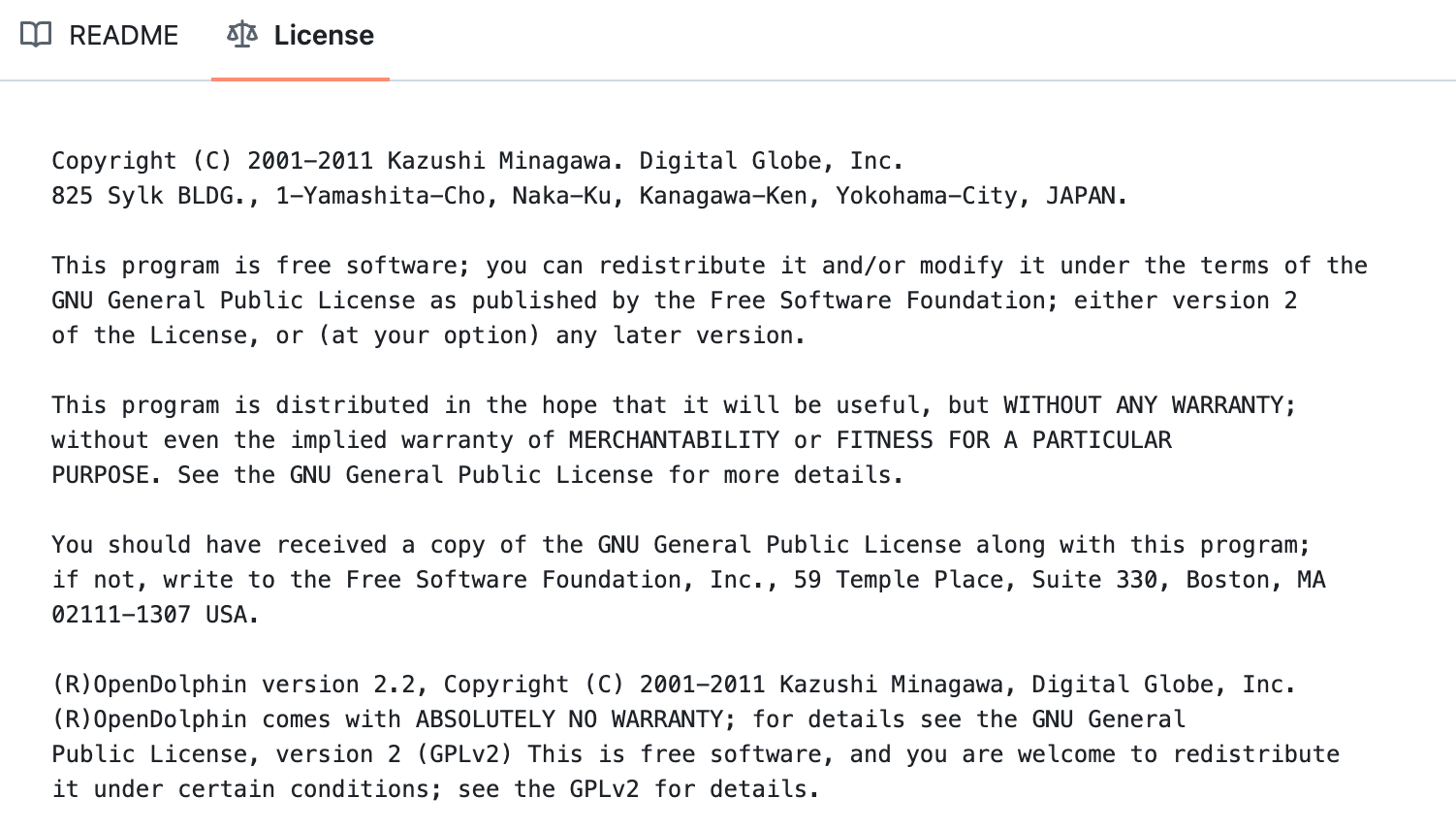
Copyright (C) 2001-2011 Kazushi Minagawa. Digital Globe, Inc.
825 Sylk BLDG., 1-Yamashita-Cho, Naka-Ku, Kanagawa-Ken, Yokohama-City, JAPAN.
This program is free software; you can redistribute it and/or modify it under the terms of the
GNU General Public License as published by the Free Software Foundation; either version 2
of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY;
without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR
PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program;
if not, write to the Free Software Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA
02111-1307 USA.
(R)OpenDolphin version 2.2, Copyright (C) 2001-2011 Kazushi Minagawa, Digital Globe, Inc.
(R)OpenDolphin comes with ABSOLUTELY NO WARRANTY; for details see the GNU General
Public License, version 2 (GPLv2) This is free software, and you are welcome to redistribute
it under certain conditions; see the GPLv2 for details.
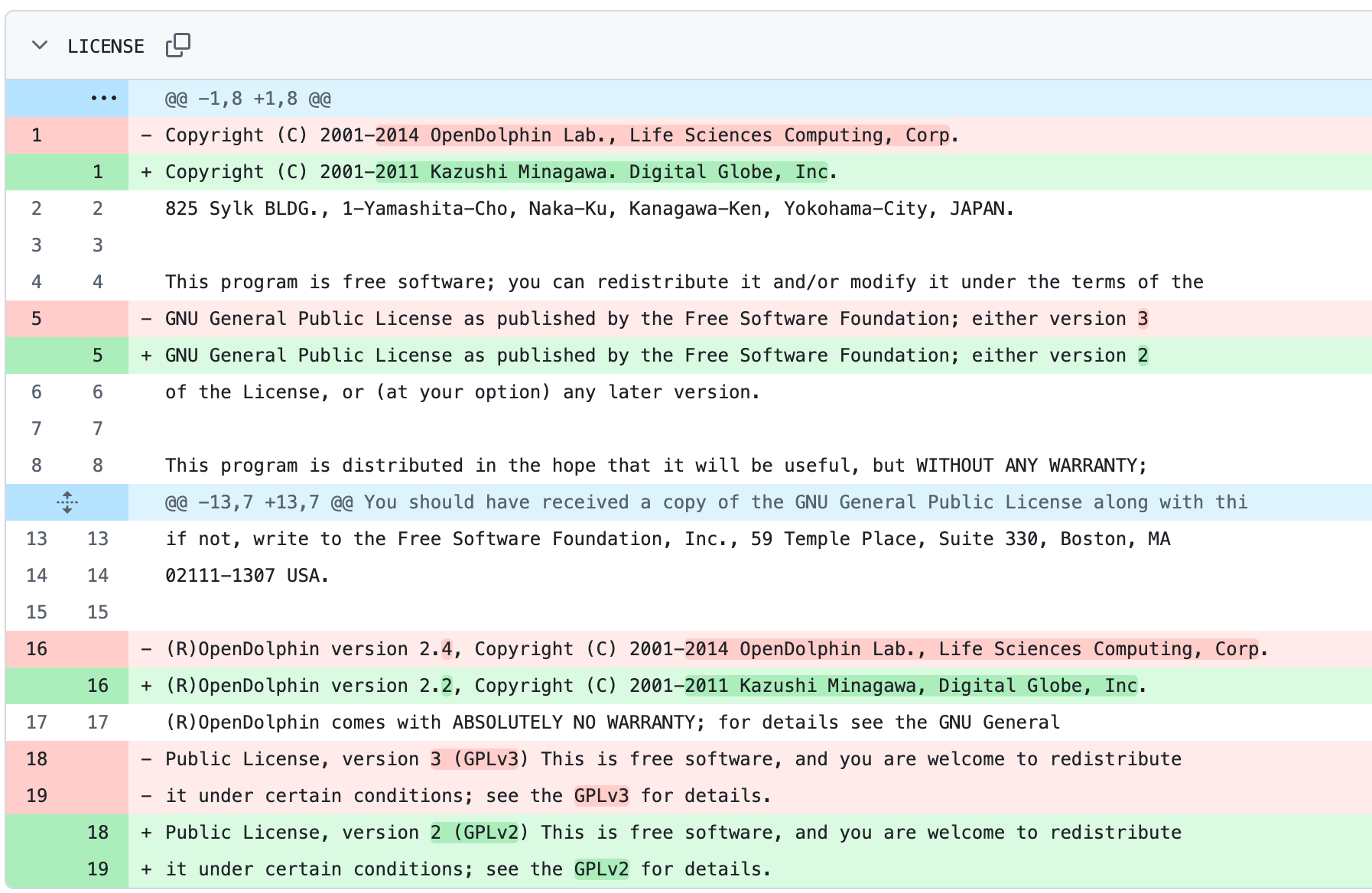
なんて記載を見たら、普通の人は v2.2 の更新し忘れだと思うのではないだろうか?(この時点でのバージョンは 2.7.1)
実際は、皆川和史が以下のように 2.4 から不自然な巻き戻し的な修正を行なった結果である。
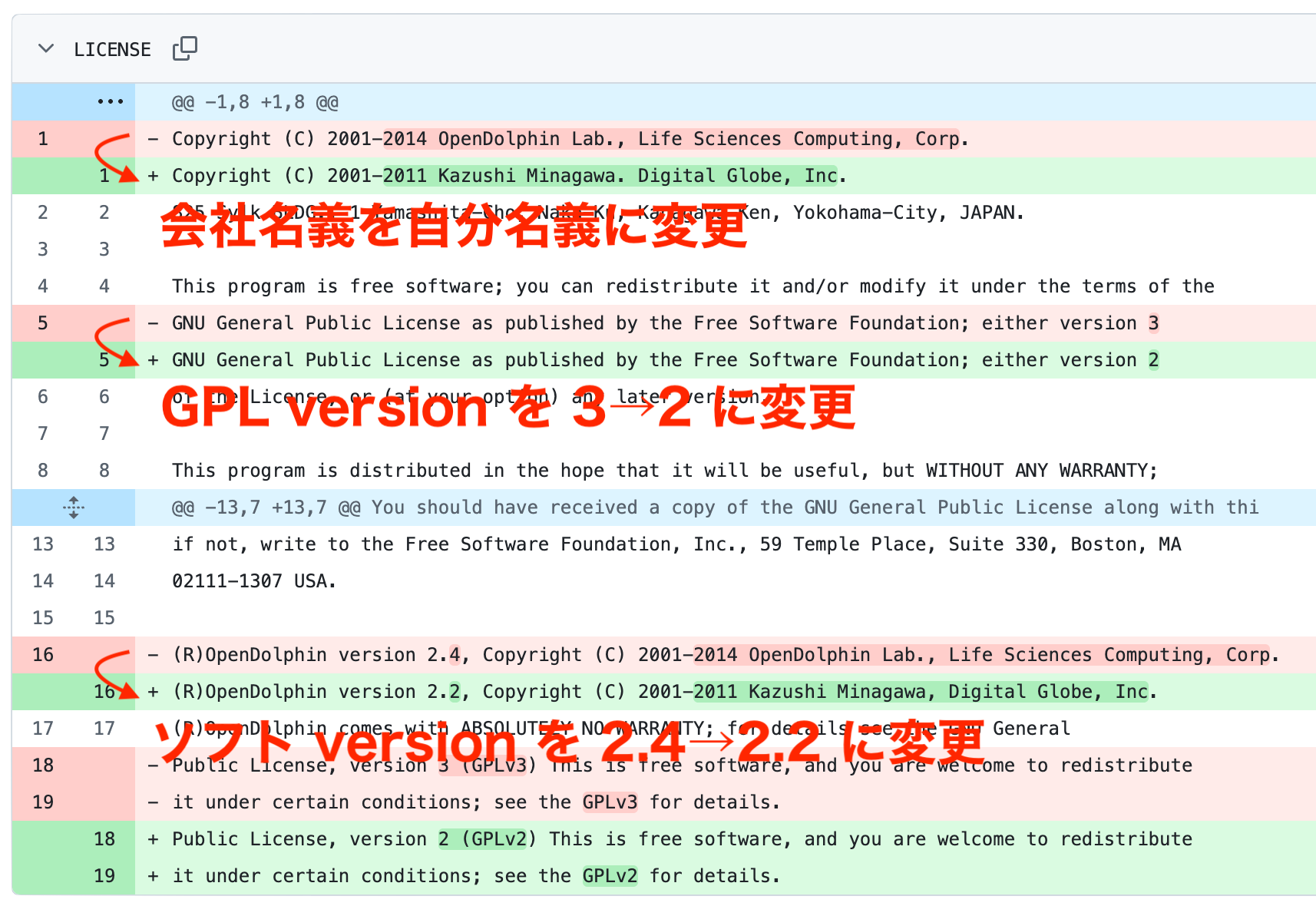
リポジトリの最終更新は 2018 で、この時点での運営元は LSC なのだから、これは皆川和史による意図的な改竄と見るのが普通で、現行の間違った記述は捨てて、LSC が fork 元であることを示すような修正が必要になってくる。
X 上でも意見交換を行なったが、今のところ、本格的に利用する際には「メドレーに確認をとった方がいいだろう」というような結論になっている。
一般には
v2.2 系・・利用しない方がいい
v2.7 系・・利用してもいいが、LICENSE 文書が改竄されていることは意識しておくこと
v2.7m 系・・手前味噌だが、推奨
だろう。
Google AI overview
ポンコツすぎる。
OpenOcean/Dolphin のライセンス周りの説明がハルシネーション出まくり。
ダメな点を挙げていく。
・皆川和史による LICENSE 文書の改竄に気がついていない
(上記参照)
・OpenDolphin は皆川和史の個人著作物という前提に立っている
少なくとも 2.7 系ではあり得ない。
・OpenOcean のオープンソースとしての利用許諾は終了している、という意味不明な主張をしている
していない。むしろ LSC はコードの利用を奨励していた。ただし、LSC dolphin 及び派生ソフトに関しては、LSC の意向で 2018 年末には GPL ライセンスは実質的に廃止されている。この事象と小林の個人的意見を取り違えている。
怪文書は当時から怪文書扱いで、あの記事の是正勧告(MOSS は法的な機関でもなんでもないのでこの言葉を使うこと自体が不適当)に従っているプロジェクトは一つもなかった。
猪股弘明
参考
『OpenOcean/Dolphin GPL LICENSE に基づくソースコード利用の指針』
パクらせてもらいました(笑)
OpenDolphinNext に関する記載は消えたりしているようですが、ANN2b 氏の言うように「AI のみで dolphin を復活させた」というストーリーは無理があるように思います。というのは、私が、データ構造に関して助言し、PR なども送ってマージされているから。
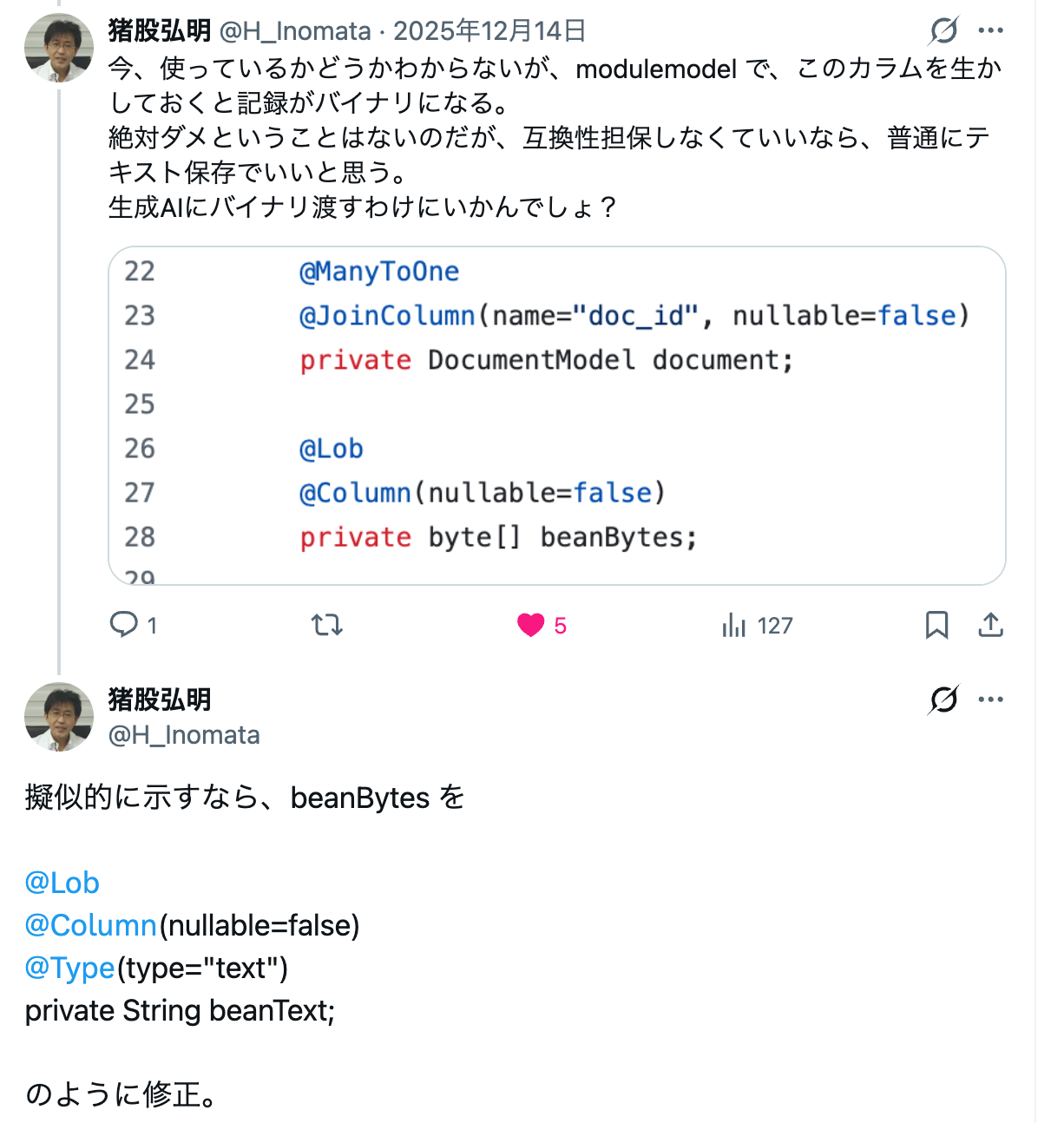
確かに PostgreSQL の保存形式としては違う(CLOB → JSONB)のですが、言わんとしていることは一緒です。
なお、彼は、私の PR が無効になっていると主張しているが、無効になっているのは、従来の dolphin 2.7系とのデータ互換性を担保している部分です。だから、(現時点 -2026年4月- ではアプリ自体が未完成だが)完成したとしても従来の 2.7 系 dolphin とはデータ互換性はまったくありません。この点には注意が必要でしょう。
『電子カルテ自作派 2022-2025』
OpenDolphinNext への軽めの言及あり。
『電子カルテ自作派 2025』
OpenDolphinNext への言及あり。
なお、「るま」という人からのコメントありますが、この人の取り扱いに当方チームは少々困りつつあります。
SNS などでは一応「医師」とは名乗っていますが、上記記事のコメント欄にもあるように、ズバリ「あなたは XX 医師なのですか?」と聞いても答えてないからです。
SNS 上での「医師」は、A 実際に医師、B 医師が運用を誰かに代行している、C 偽医師などのパターンがあり、特定が困難です。
dolphin 絡みでは、過去に B, C パターンが頻発し、コミュニティが混乱をきたしたという経緯があります。別に業者さんが絡んでいてもいいとは思いますが、当方チームが公開していたコードや各種情報を使ってこっそり商用に供していたという業者は過去にいました。あまりうるさいことを言うつもりはありませんが、あからさまな著作権法違反をやられるのは気分のいいものではありません。
権利を主張するのであれば、出自や主張の根拠をもう少し、すっきりさせて欲しいなと思います。