保護中: オープンソースの世界 -OpenDolphinNext-

Just another PHAZOR Blog

オープンソースソフトウェアは私物化、いわゆる「パクリ」との戦いという一面は確かにある。
『オープンソースはパクリの温床』という記事で以下の表現があった。
パクリのためのギミック
上の事例で気がつくのは、衆人環視のオープンソースの世界では、単純なパクリは通用せず、なんらかの仕掛け(ギミック)が必要だということだ。
オープンソースライセンスであったり、バイブコーディングであったり。
確かに確かに。
dolphin プロジェクトでもオープンソースライセンスの author 表記を改ざんする事案はあった。
バイブコーディングによるあからさまな「ライセンスロンダリング」はこれまでなかったように思うが、今後は出てくるかもしれない。
OSS ライセンスは author 権利保護という観点から見ると強力だが、注意を怠ると無効化される危険性はゼロではない。
2026/3/31 に ORCA の CLAIM が廃止になる。
dolphin 2.7 系は、ORCA との接続に CLAIM を使っていたから、CLAIM 廃止に伴って電子カルテとしては実質的に使えなくなる。
さらば、という感じだ。
オープンドルフィンといえば、open source であることが特徴とされていたが、では、その特性が生かされた利用はされていたかといえば、ほとんどされていなかったのではなかろうか。ソースコードからビルド、くらいのことはできても、導入した各施設が自由自在にカスタマイズを施す、というような、当初想定されていた利用方法を実行できた施設はほとんどないと思う。
そういう意味では失敗プロジェクトだったと思うのだが、これについて思うところを書く。
ドルフィンのリポジトリを見て気がつくことは、技術的なドキュメントが極端に少ないということだ。
各施設でのカスタマイズを促すということであれば、ソースコードが何を意味しているかなどの解説は必須だと思うが、こういうものは一切なかった。
運営する側はむしろそういった情報の提供を制限していたように思える。
また、コードの書き方がいささか本格的すぎた。例えば、デザインパターンを使いまくっているせいで、可読性が著しく低下している。
普及を阻んだ最大の要因はこれだったのではないかと思う。
(続く)

2025 後半に OpenOcean/Dolphin の著作権表示に関する記事をいくつか書いた。
その目的は、間違いだらけの AI まとめ対策のほかにソースコードを利用するための指針を示すという意図もあった。
最近では、@MedRecMate さん(丸口勇人先生?)が dolphin のソースコードを OpenDolphinNext で再利用している。
LICENSE の改竄はなかなか気がつきにくいところだ。
Copyright (C) 2001-2011 Kazushi Minagawa. Digital Globe, Inc.
825 Sylk BLDG., 1-Yamashita-Cho, Naka-Ku, Kanagawa-Ken, Yokohama-City, JAPAN.This program is free software; you can redistribute it and/or modify it under the terms of the
GNU General Public License as published by the Free Software Foundation; either version 2
of the License, or (at your option) any later version.This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY;
without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR
PURPOSE. See the GNU General Public License for more details.You should have received a copy of the GNU General Public License along with this program;
if not, write to the Free Software Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA
02111-1307 USA.(R)OpenDolphin version 2.2, Copyright (C) 2001-2011 Kazushi Minagawa, Digital Globe, Inc.
(R)OpenDolphin comes with ABSOLUTELY NO WARRANTY; for details see the GNU General
Public License, version 2 (GPLv2) This is free software, and you are welcome to redistribute
it under certain conditions; see the GPLv2 for details.
なんて記載を見たら、普通の人は v2.2 の更新し忘れだと思うのではないだろうか?(この時点でのバージョンは 2.7.1)
実際は、皆川和史が以下のように 2.4 から不自然な巻き戻し的な修正を行なった結果である。
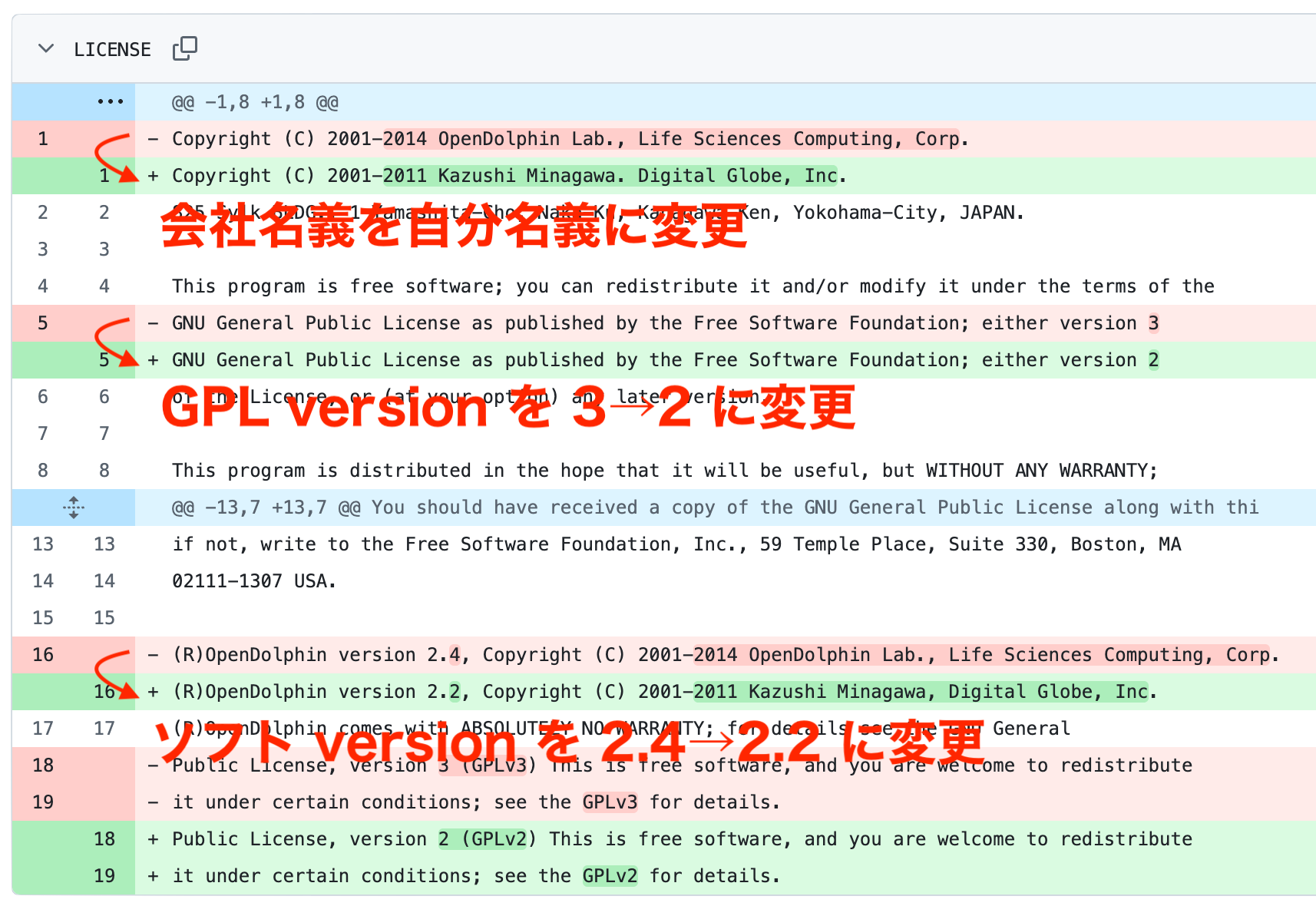
リポジトリの最終更新は 2018 で、この時点での運営元は LSC なのだから、これは皆川和史による意図的な改竄と見るのが普通で、現行の間違った記述は捨てて、LSC が fork 元であることを示すような修正が必要になってくる。
X 上でも意見交換を行なったが、今のところ、本格的に利用する際には「メドレーに確認をとった方がいいだろう」というような結論になっている。
一般には
v2.2 系・・利用しない方がいい
v2.7 系・・利用してもいいが、LICENSE 文書が改竄されていることは意識しておくこと
v2.7m 系・・手前味噌だが、推奨
だろう。
ポンコツすぎる。
OpenOcean/Dolphin のライセンス周りの説明がハルシネーション出まくり。
ダメな点を挙げていく。
・皆川和史による LICENSE 文書の改竄に気がついていない
(上記参照)
・OpenDolphin は皆川和史の個人著作物という前提に立っている
少なくとも 2.7 系ではあり得ない。
・OpenOcean のオープンソースとしての利用許諾は終了している、という意味不明な主張をしている
していない。むしろ LSC はコードの利用を奨励していた。ただし、LSC dolphin 及び派生ソフトに関しては、LSC の意向で 2018 年末には GPL ライセンスは実質的に廃止されている。この事象と小林の個人的意見を取り違えている。
怪文書は当時から怪文書扱いで、あの記事の是正勧告(MOSS は法的な機関でもなんでもないのでこの言葉を使うこと自体が不適当)に従っているプロジェクトは一つもなかった。
猪股弘明
『OpenOcean/Dolphin GPL LICENSE に基づくソースコード利用の指針』
パクらせてもらいました(笑)
OpenDolphinNext に関する記載は消えたりしているようですが、ANN2b 氏の言うように「AI のみで dolphin を復活させた」というストーリーは無理があるように思います。というのは、私が、データ構造に関して助言し、PR なども送ってマージされているから。
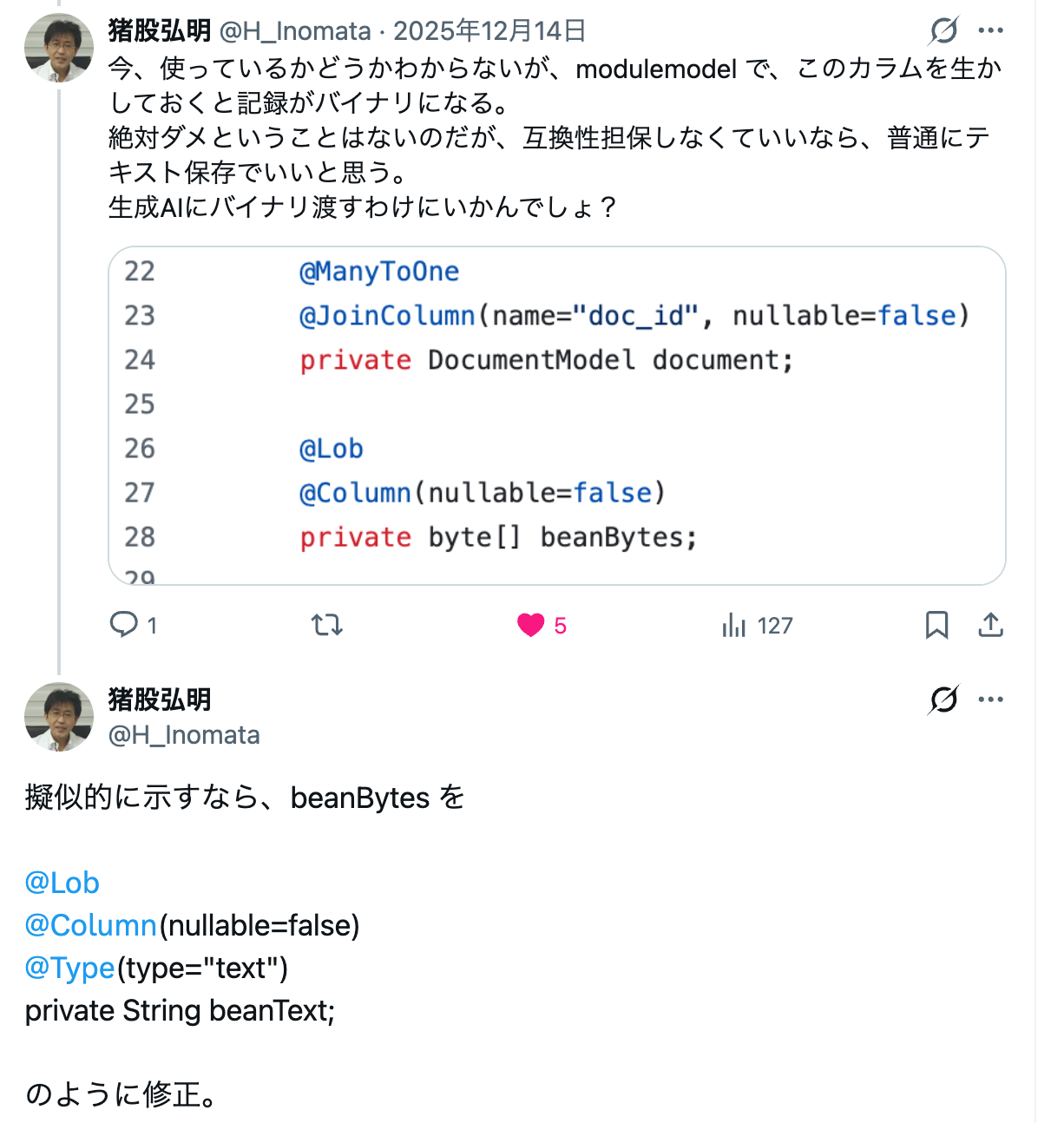
確かに PostgreSQL の保存形式としては違う(CLOB → JSONB)のですが、言わんとしていることは一緒です。
なお、彼は、私の PR が無効になっていると主張しているが、無効になっているのは、従来の dolphin 2.7系とのデータ互換性を担保している部分です。だから、(現時点 -2026年4月- ではアプリ自体が未完成だが)完成したとしても従来の 2.7 系 dolphin とはデータ互換性はまったくありません。この点には注意が必要でしょう。
『電子カルテ自作派 2022-2025』
OpenDolphinNext への軽めの言及あり。
『電子カルテ自作派 2025』
OpenDolphinNext への言及あり。
なお、「るま」という人からのコメントありますが、この人の取り扱いに当方チームは少々困りつつあります。
SNS などでは一応「医師」とは名乗っていますが、上記記事のコメント欄にもあるように、ズバリ「あなたは XX 医師なのですか?」と聞いても答えてないからです。
SNS 上での「医師」は、A 実際に医師、B 医師が運用を誰かに代行している、C 偽医師などのパターンがあり、特定が困難です。
dolphin 絡みでは、過去に B, C パターンが頻発し、コミュニティが混乱をきたしたという経緯があります。別に業者さんが絡んでいてもいいとは思いますが、当方チームが公開していたコードや各種情報を使ってこっそり商用に供していたという業者は過去にいました。あまりうるさいことを言うつもりはありませんが、あからさまな著作権法違反をやられるのは気分のいいものではありません。
権利を主張するのであれば、出自や主張の根拠をもう少し、すっきりさせて欲しいなと思います。

最近 OceanMini というアプリの制作に勤しんでいるのだが、このような新規のプロダクトに真っ先に反応するのは、最近では大手検索サービスの AI による「おまとめ」のようだ。
例えば、こんなもの。

横でちらちら眺めていると最初期の頃の明らかな間違いは時間が経つにつれ減っっていってそれはいいのだが、どうしても納得いかないことがあるので、それに関していくつかコメントしたい。
AI に限らず最近の厚労省の電子カルテに対するポリシーもこの傾向があるようなのだが、なぜか「クラウド型電子カルテ=標準」という前提に立っている。
病院で導入されている電子カルテの構成をチェック(ほとんどが院内設置のオンプレミス型)すればわかるようにこんなものは標準ではない。
近年のクリニックレベルでのクラウド(ブラウザ)タイプの電子カルテの普及は「コスパ的に見てオンプレミスよりもアドバンテージがある」というだけであって、医療記録の記載という観点から見れば、むしろデメリットの方が大きい。
例えば、医療記録であるからには、診断根拠を明記した方が良いが、画像が診断の決定的な根拠となるような場合であっても、いわゆる商用のクラウド型の電子カルテは、画像をカルテ上で展開できないか、できても枚数制限がある場合が多い。
これは商用を前提とするクラウド型では当然の話で、画像の添付やフォントの変更のできるリッチエエディタを電子カルテに採用するには
・それ自体開発コストがかかる
・採用したとしても画像の添付などはストレージに負担がかかる
という理由ゆえ避けられる傾向にある。
つまり、リッチエディタを採用しないのは医学的な理由からではなく商業的な理由からだ。
このような背景は、この分野である程度技術に明るい人からすると当然の話であって、それをなんで「商用ではないからダメだ」みたいなレビューのされ方されなきゃいけないんだろう?
個人開発よりいくらかマシな程度の「有志コミュニティ」による開発体制なので、商用電子カルテと比較されるのは致し方ないが、間違った理由で間違ったデメリットを列挙されるのは違うと思う。
ちょっと愚痴っぽくなったが、こういった背景事情を踏まえて OceanMini ではリッチエディタを採用した。

例えば上の症例は、経過+画像で診断の当たりがつくのであって、これを文字情報のみにしたら(法律的にはダメではないと思うが)直感的な表現という意味では物足りないものになってしまう。
繰り返すが、医学的な記録の記載ツールとしてはより良い選択肢と思われるリッチエディタの採用は商用のクラウド型ではないから容易に実現できたことだ。商用のクラウド型=標準と捉えるとこのような特徴は見落とされてしまう。
甚だ遺憾だ。
AI によるまとめなどでは特に強調もされていないようだなのだが、OceanMini は小さなアプリながら、医療機関が提供するサービス形態、つまり外来・訪問診療・入院のすべてに対応している。
商用ベンダーが、電子カルテを外来診療所向け・訪問診療所向け・病院向けのプロダクトを分けて開発・販売しているのは、これもおそらく商業的な理由からであって、私らはそんなことは気にする必要もないから、開発プロセスの重複を避けるためにそうしている。
この特徴も商用電子カルテを基準に考えると見落とされてしまうと思う。
もちろん、実装上の工夫はしている。
その際たるものは Patient Pool という設計思想だ。
Patient Pool に関してはそのうちどこかにまとめようと思うが、一言で言うなら「外来・訪問・入院といったサービスごとに対象患者を専用のテーブルにステージングしておき、電子カルテはこのテーブルを介して患者データにアクセスする」という設計思想だ。

この設計を実装に落とし込んでいるからこそ OceanMini は一つのアプリで複数のサービスに対応できているのだ。
が、商用のプロダクト展開を当然としてしまうとこういった特徴は見逃されてしまう。
これも遺憾だ。
商用のクラウド型である限り、その出自由来の制約もあるのだから、そのことに言及しないのは片手落ちと言えるだろう。
また、商用ベンダーの対外的な広報も全面的に信用できるものではない。
例えば、改正医療法の解釈に関して、クラウド型の電子カルテを提供している企業の中にはさも「クラウドネイティブタイプの電子カルテの医療機関への(強制)導入が法律で決まった」かのような広報をしているところがあったが、厚労省は方針と数値努力目標を示しただけであって、条文レベルではそんなことは一言も言っていない。

OceanMini は「Mac 専用」と紹介されることが多いようだ。
これは確かに事実だし、制作意図もそれを強く意識したもの(Mac 専用のローカルで動く電子カルテが本当に少ない)だったが、もともと DolphORCA ベースだし、開発言語もわざわざ C/C++/Obj-C を選んでいるのだから、移植しやすさに関しては注意を払って欲しかった。
実際、OceanMini のコードのかなりの部分は 、pure C/C++ で書かれており、先日、Linux サーバプログラムとして書き直したもの(OceanMiniCloud と呼んでいる)を某サーバに試しに deploy した。
C++ ベースだけあって、実にきびきび動いた。
以上、とりあえず目についたレビューの気になった点についてコメントしてみた。
また気になることが出てきたら、追記します。
精神保健指定医, OceanMini 開発者
猪股弘明